
Website Metadata & Content Scraper GPT - comprehensive web data extraction

Welcome! How can I assist with your webpage data needs today?
Unlock Web Insights with AI
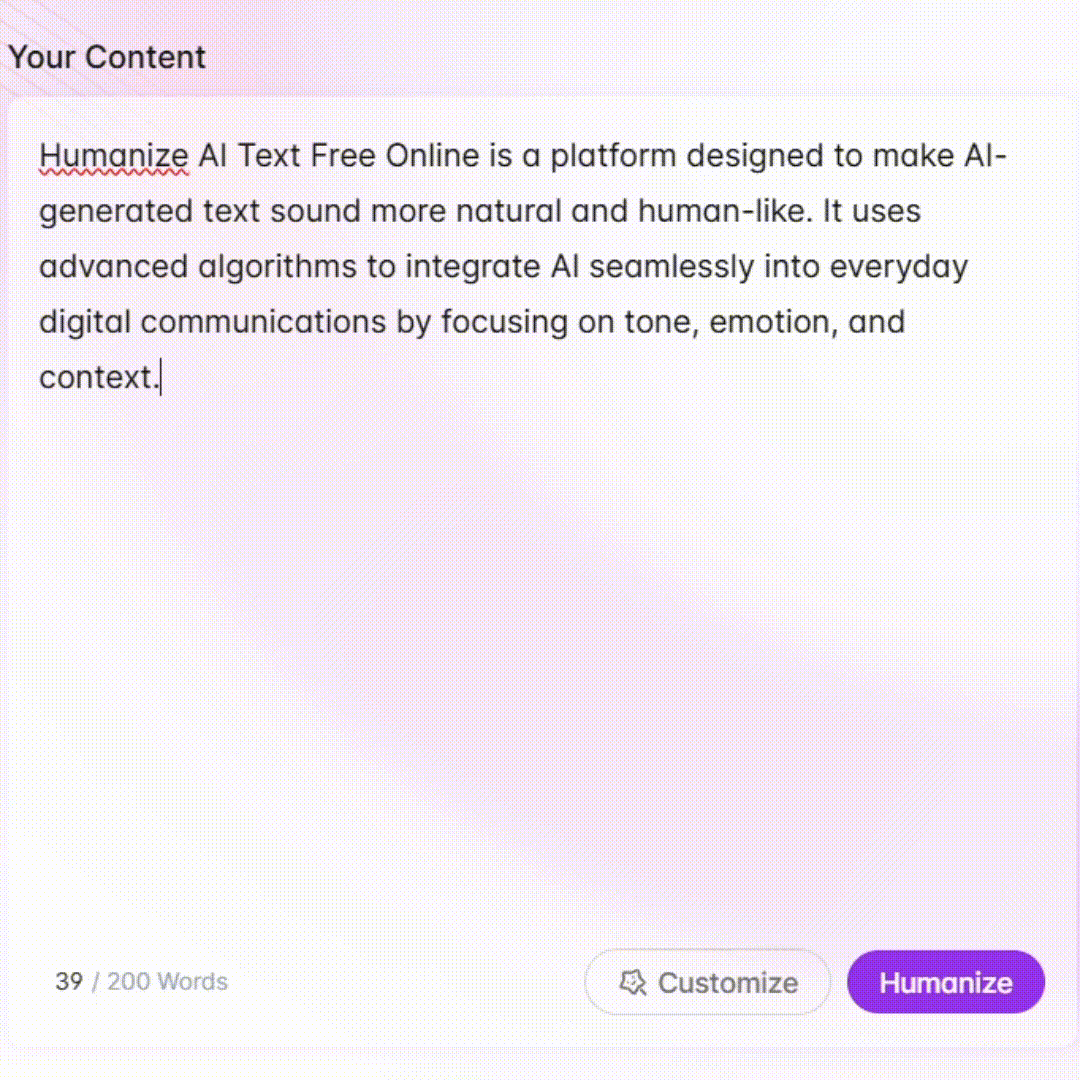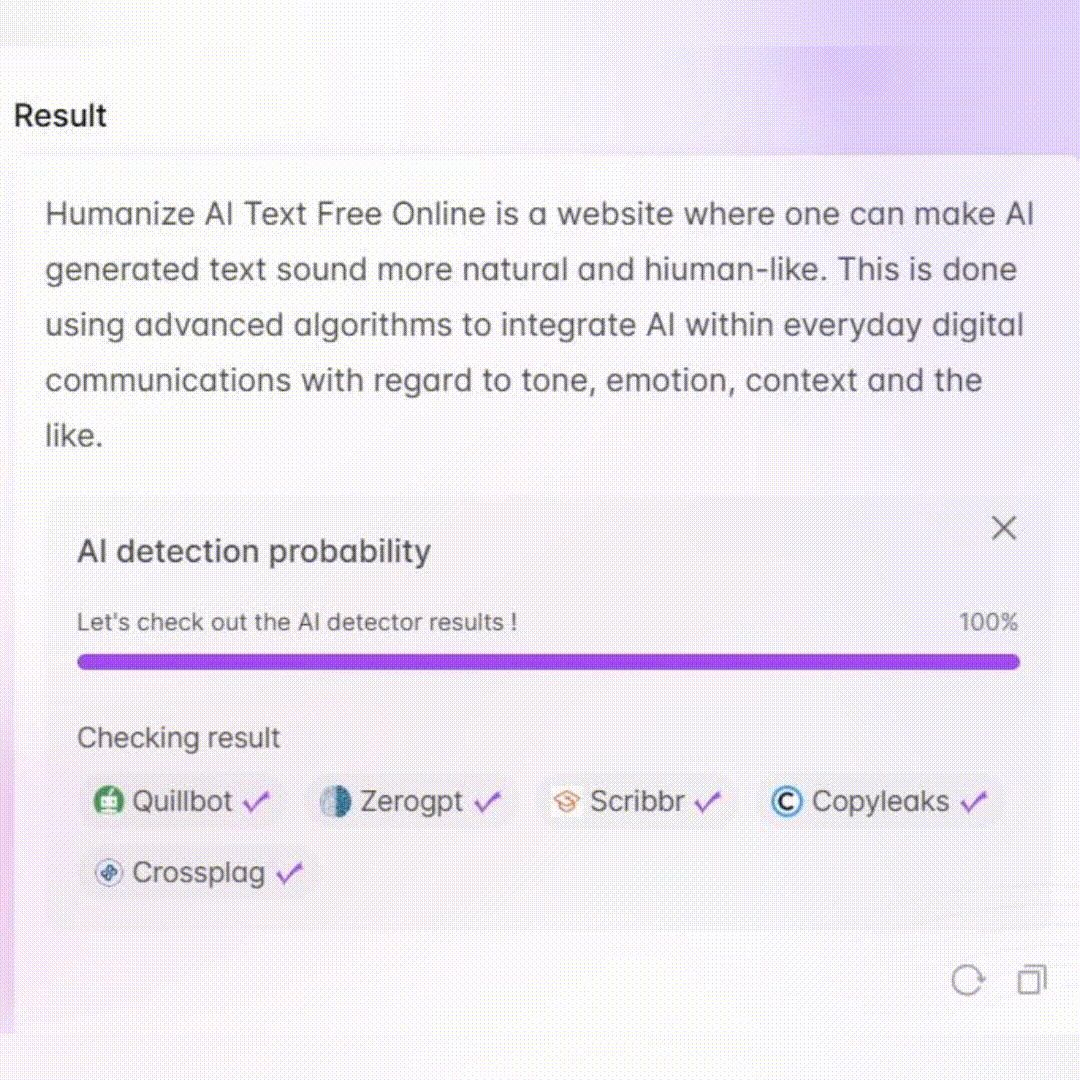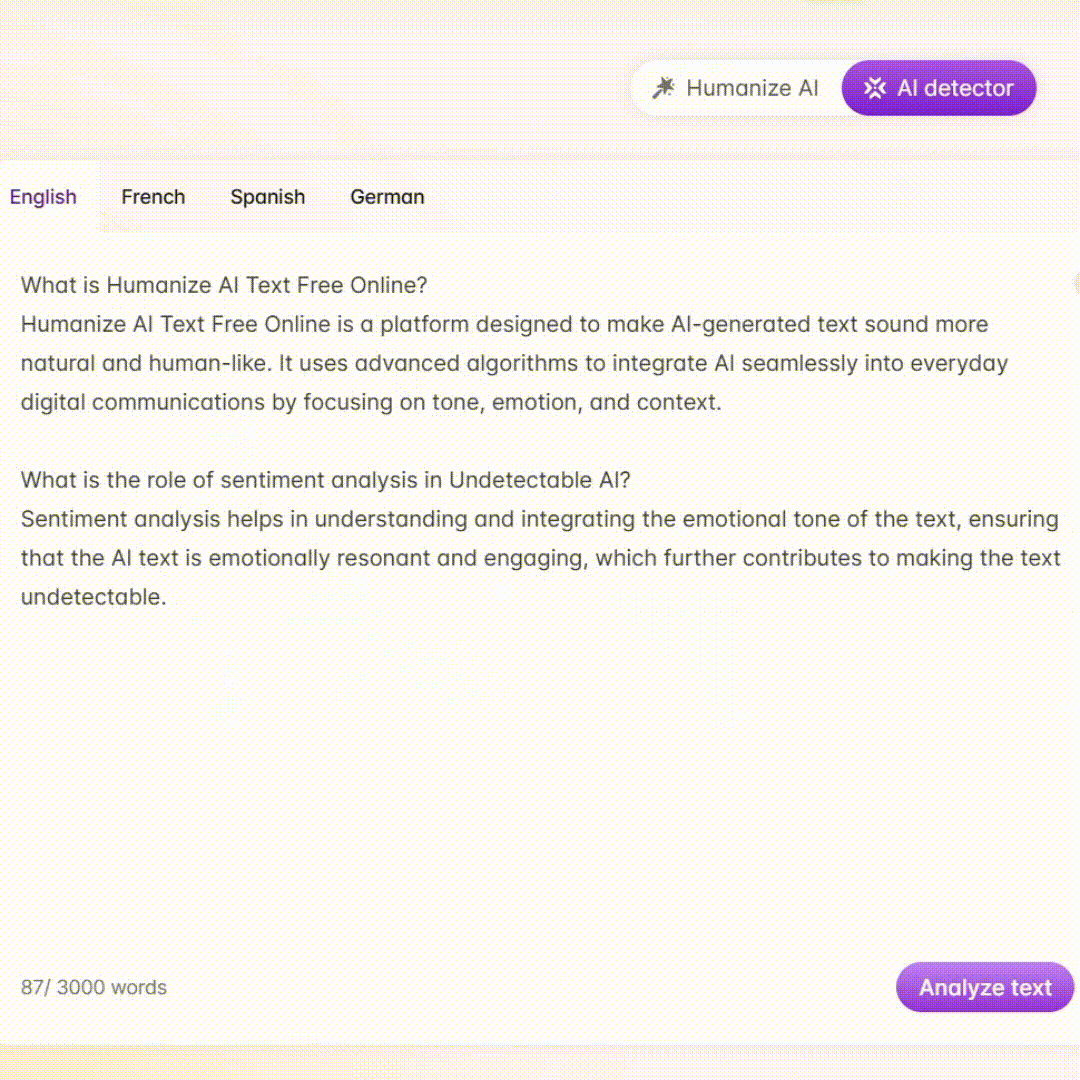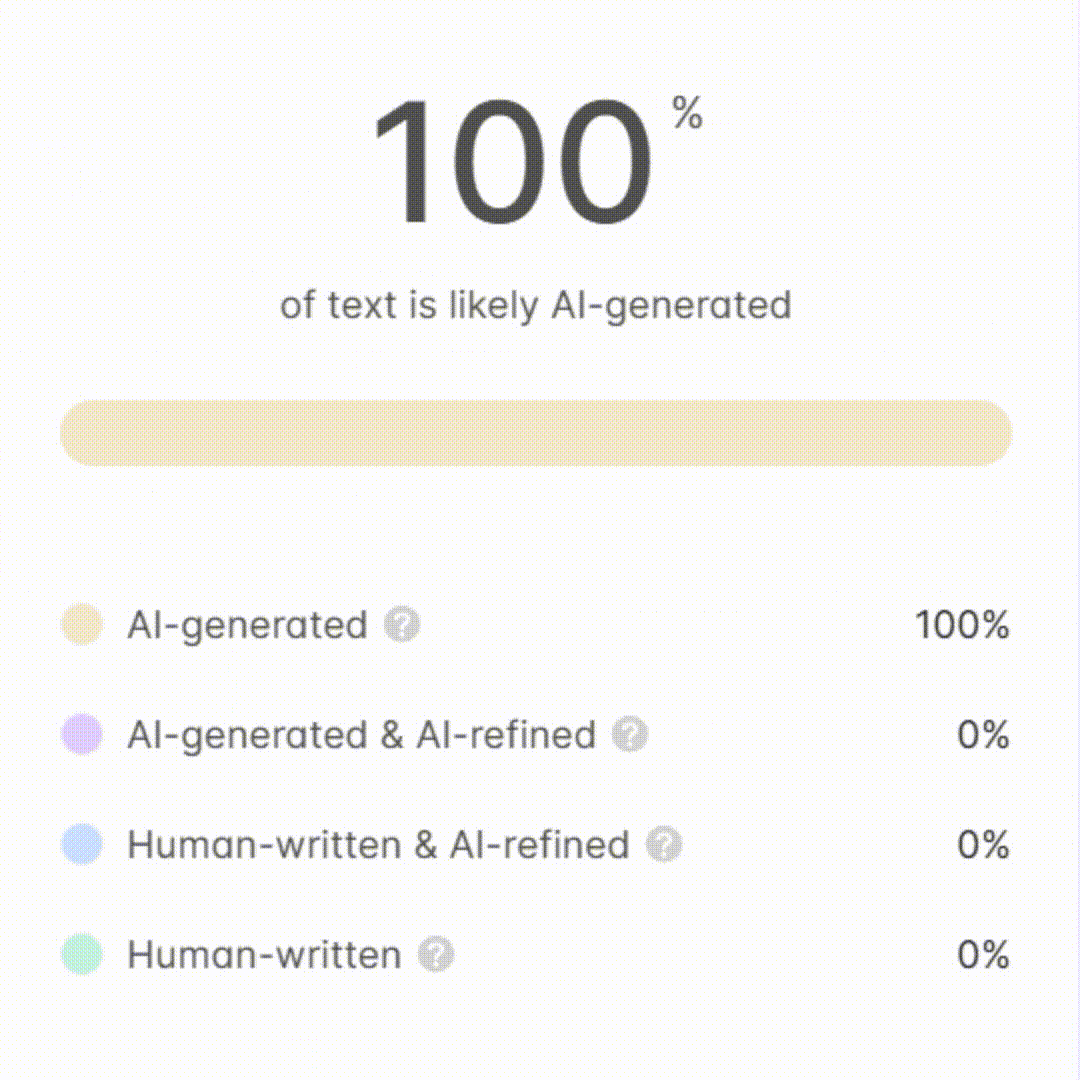
Get metadata only for my URL
Get content only for my URL
Get all data for my URL
Show me example metadata
Get Embed Code

WebPilot GPT
Read and Scrape Websites and Gather Data

ScrapeGPT
Extract data from websites

AI ScrapingGPT
Efficiently scrape websites and return data in JSON.

Web Scrape GPT
Combines up to date web info with GPT analysis.

GPT 智能爬虫
A web crawler GPT providing concise, factual web data

GPTWebScraper
Your guide for efficient web scraping. Type 'help' to read instructions. v1.1
Introduction to Website Metadata & Content Scraper GPT
Website Metadata & Content Scraper GPT is a specialized version of ChatGPT designed to retrieve and analyze web content and metadata. Its primary function is to assist users in gathering detailed information from web pages, including metadata like title, description, logos, and color palettes, as well as comprehensive content in various formats (PDFs, screenshots, etc.). By leveraging the Microlink API and custom instructions, this GPT offers accurate and formatted data retrieval for a wide range of web scraping needs. Example Scenario: A user needs to analyze the SEO strategies of competitors by collecting metadata like titles and descriptions across their websites. By providing the URLs to this GPT, they receive a detailed, structured report of all relevant metadata. Powered by ChatGPT-4o。

Main Functions of Website Metadata & Content Scraper GPT
Get all data for a URL
 Example
ExampleRetrieves everything including metadata (title, description, logo), screenshots, PDFs, and the entire page content.
ScenarioA digital marketing agency needs to create a comprehensive report of their client's competitors' web pages. By passing a list of competitor URLs to this GPT, they obtain full metadata, screenshots, color palettes, PDFs, and the entire page content in a neatly formatted table.
Get metadata only for a URL
ExampleRetrieves only essential metadata like title, description, logo, and screenshot.
ScenarioA blogger is researching for SEO purposes and needs to quickly compare the titles and descriptions of top-ranking websites in their niche. They input the URLs into this GPT and receive a report containing just the metadata.
Get content only for a URL
ExampleProvides the entire content of a webpage in PDF format and extracts all 'h1, h2, h3, h4, p, a' tags.
ScenarioA journalist is compiling a report about a particular company's policies. They input the URL of the company's website and receive a PDF of the entire content along with structured tags, enabling quick access to relevant data.
Extract dominant color palette
ExampleAnalyzes the main image and extracts dominant color palettes (vibrant, muted, dark vibrant, etc.).
ScenarioA graphic designer is developing a new website theme for a client and needs to ensure consistency with the client's brand. They input the client's website URL to this GPT and receive a structured color palette, aiding their design decisions.
Generate webpage screenshots
ExampleCaptures a full-page screenshot of the given webpage.
ScenarioA project manager needs to keep visual records of a website's design evolution for their portfolio. They input the URL and receive a high-quality screenshot.
Generate webpage PDFs
ExampleCreates a PDF version of the entire webpage for offline reading or archiving.
ScenarioA legal researcher needs to archive specific pages from various government websites for future reference. By providing the URLs, this GPT returns PDF versions of those pages.
Ideal Users of Website Metadata & Content Scraper GPT
Digital Marketers and SEO Specialists
Digital marketers and SEO specialists can use this GPT to conduct competitive analysis by quickly gathering metadata and content from various competitor websites.
Content Creators and Bloggers
Bloggers and content creators can easily compare content strategies or gather relevant information by retrieving PDFs and tags of their favorite sites.
Researchers and Journalists
Researchers and journalists benefit from quick access to comprehensive web page content and metadata, enabling detailed analyses of topics and subjects.
Web Designers and Graphic Designers
Designers receive accurate color palettes, screenshots, and other visual assets that help maintain brand consistency or inspire new designs.
Product Managers and Developers
Product managers and developers can archive versions of websites and keep a visual record of design changes over time for documentation purposes.
Legal and Compliance Teams
Legal teams can archive webpages for compliance and future reference using PDF or screenshot functionalities.
Using Website Metadata & Content Scraper GPT
Initial Setup
Visit yeschat.ai to try out Website Metadata & Content Scraper GPT without needing to log in or subscribe to ChatGPT Plus.
Enter URL
Provide the URL of the webpage from which you want to extract metadata or content.
Select Mode
Choose the type of data you need: 'All Data', 'Metadata Only', or 'Content Only' depending on your requirements.
Review Output
Examine the extracted data presented in a structured table format including screenshots, PDFs, and detailed webpage content.
Further Interaction
Option to request more detailed content by specific tags such as 'h1', 'h2', etc., if needed for deeper analysis or documentation.
Try other advanced and practical GPTs
CompanionCube
AI at your service

AI Correct Score Betting Tips
AI-driven correct score betting predictions

Spintax Generator Pro 2.0
Revolutionize Content with AI-Powered Spinning

AI for PRODUCT PEOPLE
Empowering Product Decisions with AI

LinguaBridge
Translating Text, Bridging Cultures

Art
AI-powered creativity unleashed

Cheeky GPT
AI-driven wit and wisdom.

Oracle's Advisor
Insightful AI, Powerful Results

Taalmeester
Master Dutch with AI-Powered Guidance

Prompt Architect GPT
Craft Precise Prompts, Unlock Powerful AI

GPT Craftsman
Craft Your Own AI Expert

CineTech Assistant
Intelligent Filmmaking Tools Powered by AI

FAQs on Website Metadata & Content Scraper GPT
What is Website Metadata & Content Scraper GPT?
This tool is designed to extract detailed information from webpages, including metadata, all page content in HTML, screenshots, and even PDFs of the page for analysis and use in various digital projects.
Can I extract data from any website?
Yes, you can use this tool to extract data from most public websites. However, ensure you have the right to use the data in your intended manner, especially for commercial purposes.
What are the common use cases of this tool?
Common uses include SEO analysis, content retrieval for research, competitive analysis, and archiving or documentation purposes.
How does this tool handle dynamic content?
The tool can prerender dynamic websites to capture the fully rendered HTML content, ensuring you get comprehensive data including content generated by scripts.
Is there a limit to the number of requests I can make?
The number of requests might be limited based on server capacity and fair usage policy to ensure optimal service for all users.